|
|
|
|
|
|
A. List five ways to minimize the lost in space problem?
B. List five ways to minimize the time-consuming menu problem?
3-2 Even in the best of situations, speech recognition engines sometimes fail to correctly convert speech to text. List five ways application designers can minimize this problem?
3-3 Even in the best of situations, speaker identification and verification sometimes fail to correctly identify/verify the caller. List five ways application designers can minimize this problem?
3-4 Construct a language identification prompt by doing the following: A. Choose an area somewhere in the world and identify the primary spoken national language and two secondary languages used in that area.
B. Construct an explicit selection menu that asks callers which of the three languages they prefer to speak. Assume that a native speaker of the language will prerecord each prompt, so you only need to specify what the native speaker should say. E.g., write the words for the prompt. Assume that the caller will respond with the English name of the spoken national language.
C. Repeat (b). Assume that an English speech synthesizer will speak each prompt. You will need to use a phoneme markup command to describe the phonemes in the prompt. The phoneme command is described in the Speech Synthesis Markup Language document on the W3C Voice Browser Working Group web site: http://www.w3.org/voice. The phoneme markup command requires the use of a phonetic language. Use the Worldbet phonetic language described on the Oregon Health and Sciences University web site at http://cslu.cse.ogi.edu/tutordemos/SpectrogramReading/ipa/ipachars.html.
D. Repeat (b) Assume that the speech recognition engine recognizes the local pronunciation of the names of the three spoken national languages. Write down the local pronunciation of the names of the two spoken national languages using the Worldbet phonetic language. (In practice, this notation is placed in a lexicon, which is used by the speech recognition engine to recognize words.) For example, "English" would be denoted as "E N l I S".
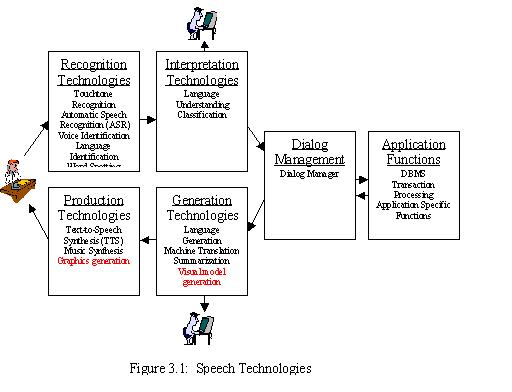
3-5 PDA's currently have displays for presenting information to the user, and both keys and a stylus for obtaining information from the user. Telephones have speakers for presenting information to the caller, and both keys and a microphone for obtaining information from the caller. Suppose that a new device is constructed having all the modes of input of both current PDAs and telephones. What additions should be made to Figure 3.1 to support these multiple modes of input and output?
a |